# OpenResty实践
# 引言
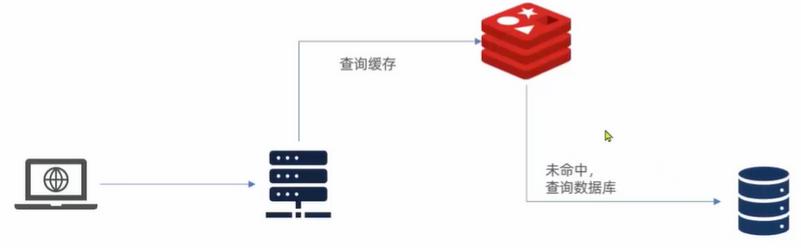
我们来说说传统缓存的问题
用户请求达到tomcat后,先查询redis再到数据库,但是tomcat的连接是小于redis的,所以并发度较低,那么就会造成一个Tomcat的性能成为整个系统的瓶颈。
Redis缓存失效后,会直接对数据库进行冲击(也就是缓存击穿现象:没有并且对着没有的地方进行冲击)
# 优化缓存方案
nginx跟tomcat差不多,除了做反向代理之外还能自己编写业务->这里作为缓存;
1.我们的浏览器作为客户端的缓存,比如静态资源,当访问相同的静态资源时做出响应;
2.nginx:缓存我们的动态数据,在请求还没有到底tomcat时候,如果nginx中缓存了该数据就响应,如果没查到就去redis查,之前是在tomcat后查,现在是在nginx后查;
3.进程缓存:在redis缓存没有被命中的时候->到达tomcat,在服务器内部利用类似map保存数据,如果命中就返回;
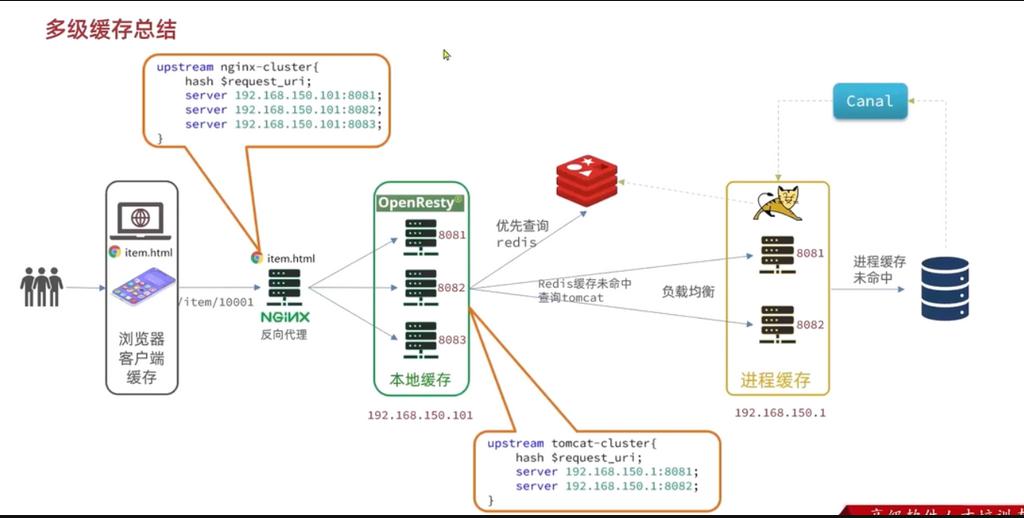
# 多级缓存说明
有个静态页面item.html放在了windows上面的Nginx,充当静态资源服务器和反向代理服务器。
当用户请求的时候将页面返回用户的浏览器,当浏览器渲染页面的时候,发现缺少数据,就会发送Ajax请求来查询数据,那么windows的Nginx不会处理,而是反向代理给Linux中的Nginx集群。该集群也是一个本地缓存数据。所以说是返回数据的第一站。负载均衡根据id固定请求一个服务器。
如果Nginx本地缓存未命中,则去查询Redis缓存。Redis是缓存第二站。
如果Redis缓存未命中,再根据id负载均衡的请求,JVM的Tomcat进程缓存。JVM进程缓存第三站。
如果三级缓存都未命中,再去mysql数据中查询数据。
# 引入OpenResty的好处
1.这样层层缓存到达tomcat的请求就会减少,而Tomcat的性能就不会成为系统的瓶颈,我们之前的层层剥削也就是为了解决因为tomcat而导致并发量较低的情况。
所以说,我们在一定程度上还提高了并发量。
2.减少对于数据库的冲击,在一定程度上防止了缓冲穿透
# 什么是OpenResty
OpenResty是一个基于Nginx的高性能Web平台,用户方便的搭建能够处理高并发、扩展性极高的动态Web应用、Web服务和动态网关。具备以下特点:
具备Nginx的完整功能
基于Lua语言进行扩展,集成了大量精良的Lua库、第三方模块
允许使用Lua自定义业务逻辑、自定义库
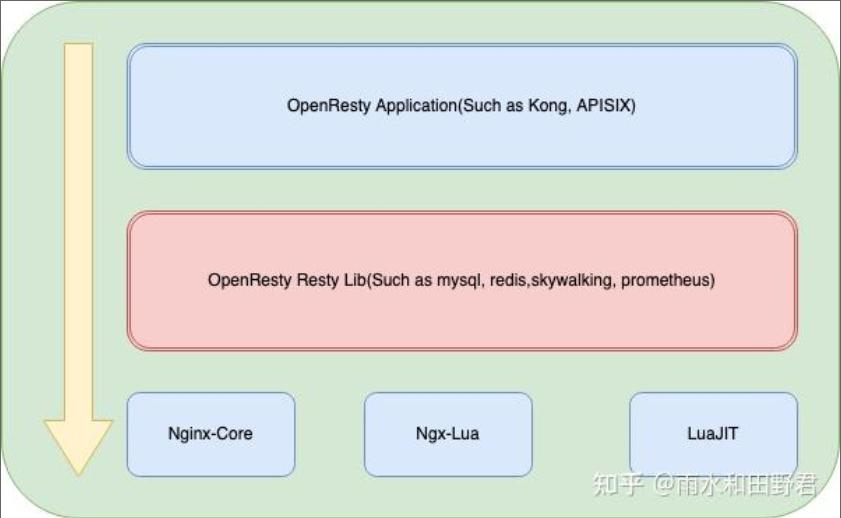
OpenResty 的架构主要分为五部分:
1 Nginx Core:Nginx 的核心,提供了 HTTP 服务器的核心功能,包括处理请求、转发请求、处理静态文件请求等。
2 LuaJIT:高性能的 Lua 解释器,用于解释执行 Lua 代码,并且能够非常快速地与 Nginx Core 集成。
3 NGX-Lua: 即ngx_http_lua_module ,将Lua的能力构建到Nginx Core内核里面。
4 Resty 模块库:包括第三方模块、官方模块和 OpenResty 扩展模块,提供了更多功能,如访问数据库、缓存、内存共享等。
5 OpenResty应用:基于OpenResty开发的应用,如APISIX API Gateway,Kong Gateway等。
2
3
4
5
6
#
# 安装和使用
-- 下载安装包:从 OpenResty 官方网站下载适合您操作系统版本的安装包,如:64 位操作系统:https://openresty.org/download/openresty-1.17.8.2.tar.gz
-- 解压安装包:使用 tar 命令解压下载的安装包:
cd /path/to/installation/package
tar -zxvf openresty-1.17.8.2.tar.gz
-- 安装依赖包:安装 OpenResty 所需的依赖包,如:
yum install gcc pcre-devel openssl-devel
-- 编译安装:在解压的 OpenResty 目录下执行编译和安装命令:
cd openresty-1.17.8.2
./configure
make
make install
-- 配置环境变量:添加 OpenResty 的安装目录到环境变量中,以便在任意目录下使用 OpenResty 命令:
echo 'export PATH=$PATH:/usr/local/openresty/bin' >> ~/.bashrc
source ~/.bashrc
2
3
4
5
6
7
8
9
10
11
12
13
14
以上步骤完成后,您已经成功安装了 OpenResty。您可以通过在命令行中输入 openresty 来验证是否安装成功。
# Hello World
配置置Nginx:在Nginx配置文件中添加以下代码,以使Nginx可以使用Lua脚本:
location /lua {
content_by_lua_block{
gx.say("Hello, World!")
}
}
2
3
4
5
启动OpenResty,在浏览器中访问"http://localhost/lua",将看到"Hello, OpenResty!"的输出。
# redis插件的使用
# 安装redis插件
luarocks install redis-lua
# 在nginx.conf 中加入以下代码:
# 加载 Redis 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
# 配置 Redis 连接
init_by_lua_block {
local redis = require "resty.redis"
local red = redis:new()
red:set_timeout(1000) -- 1 sec
local ok, err = red:connect("127.0.0.1", 6379)
if not ok then
ngx.say("failed to connect: ", err)
return
end
}
# 设置请求处理脚本
server {
listen 80;
location / {
default_type text/html;
content_by_lua_block {
local redis = require "resty.redis"
local red = redis:new()
local res, err = red:get("dog")
if not res then
ngx.say("failed to get dog: ", err)
return
end
ngx.say("dog: ", res)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 重启nginx 设置redis键值
/usr/local/openresty/nginx/sbin/nginx -s reload
Redis 中存储数据
$ redis-cli
127.0.0.1:6379> SET dog "hello world"
OK
2
3
4
5
# 访问Nginx查看效果:
curl http://localhost
dog: hello world
2
# 开启共享词典
Openresty本身也支持开辟内存添加共享缓存的空间,操作api与redis一致。
本地缓存的作用:减少查询redis、mysql的操作,实际redis也很快,但是毕竟有网络开销。本地缓存会更快一些!
//nginx.conf
http{
lua_shared_dict mycache 128m; -- 获取缓存对象 使用方法时 ngx.share.XXX
content_by_lua_block {
local getCache = ngx.shared.mycache; -- 读取数据
local name = getCache:get('name')
ngx.say('读取本地缓存!',name)
getCache:set('name','zhangsan',10) -- 超时时间10秒
ngx.say('缓存设定成功!')
local name = getCache:get('name') -- 读取数据
}
}
2
3
4
5
6
7
8
9
10
11
# 应用案例
在查询商品时,优先查询OpenResty的本地缓存,需求:
1.修改item.lua中的read_data函数,优先查询本地缓存,未命中时再查询Redis、Tomcat
2.查询Redis或Tomcat成功后,将数据写入本地缓存,并设置有效期
3.商品基本信息,有效期30分钟
4.库存信息,有效期1分钟
解决方案,在tomcat之前再添加缓存,使得部分请求没有经过tomcat,提升tomcat的并发处理能力。
在各个处理环节都添加上缓存,一层一层的进行过滤,减少后面的压力,也能防止部分缓存不可用能有其他缓存抵上
核心代码
-- 封装函数,先查询redis,再查询http
local function read_data1(key, expire, path, params)
ngx.log(ngx.INFO, "path=", path)
-- 查询本地缓存
local val = item_cache:get(key)
if not val then
ngx.log(ngx.ERR, "本地缓存查询失败,尝试查询redis,key:", key)
-- 查询redis
val = read_redis("127.0.0.1", 6379, key)
ngx.log(ngx.INFO, "查询Redis数据, val = ", val)
-- 判断redis是否命中
if not val then
ngx.log(ngx.INFO, "Redis查询失败,尝试查询http")
ngx.log(ngx.INFO, path, params)
-- Redis查询失败,查询http
val = read_http(path, params)
end
end
ngx.log(ngx.INFO, "val=", val)
-- 查询成功,把数据写入本地缓存,单位秒
-- item_cache:set(key, val, expire)
-- 返回结果
return val
end
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
打个赏吧 点我,三毛五毛都是流水。